第八章:欺诈证明简介
一. RollUp
Rollup 的核心思路是在L1上保存能够验证交易过程的凭证,而将交易过程(计算过程)还有状态存储运行在L2中。
何为交易过程的凭证,我们知道交易执行的过程就是由1个状态转移到另外1个状态的过程,如果L1知道了一组交易前的状态和一组交易后的状态还有这一组交易,自然可以验证这组交易对应的状态转移是否正确。
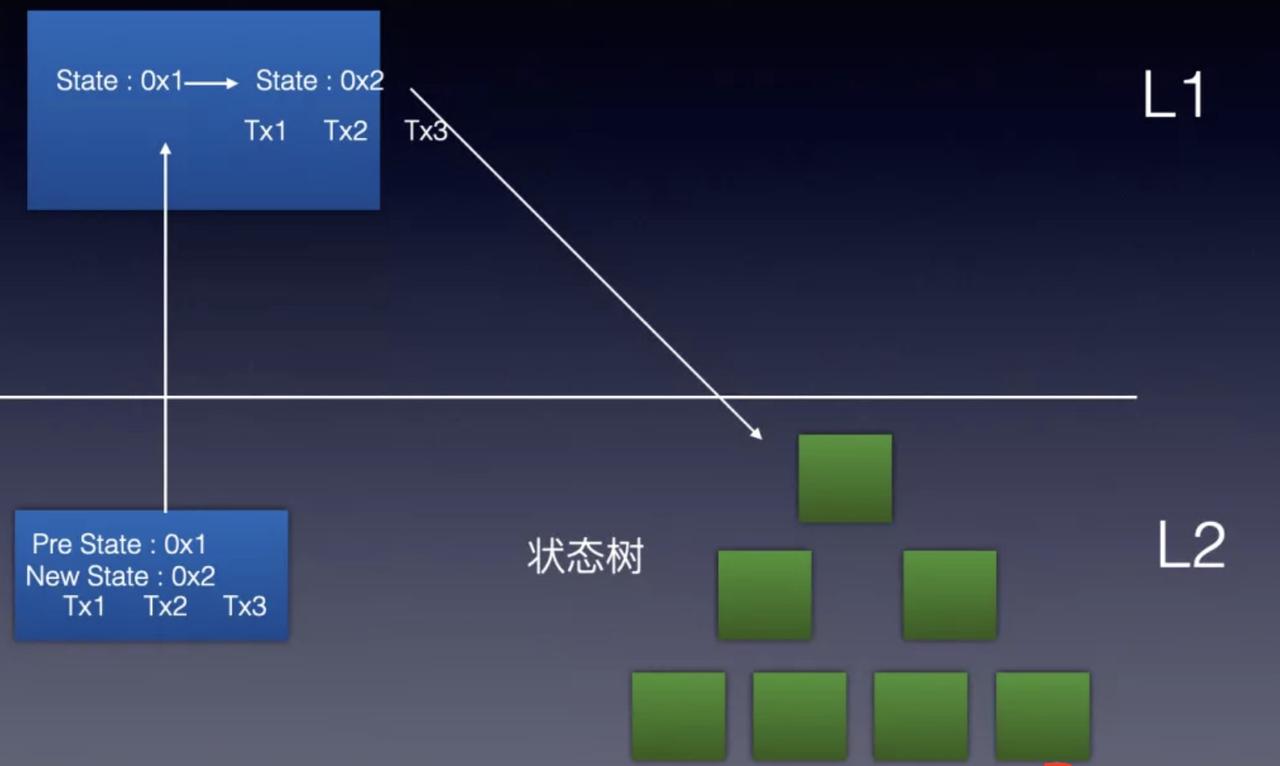
如上图所示,发布者将交易前状态树的根hash 交易后状态树的根hash以及交易发布到L1上,L1智能合约确认交易前状态树根hash是否和存储的根hash一致。交易前的根hash一致说明起始状态正确,那么本次交易过程是否正确如何验证呢?最安全的做法肯定是我们每次都在L1上重新执行L2的交易树,进行状态转移,但这样L2失去了意义,还是会面临不可能三角中处理速度的问题。
如何去验证状态转移是否正确也引出了2种不同的Layer2 Rollup机制。
第一种是欺诈证明,即默认相信存入的状态是正确的,等待其他参与者提出欺诈证明挑战,每一次L2发布到L1时的节点都要缴纳一定的保障金,当欺诈被证明后 回滚到前一状态,发布者保证金会被全部扣除,部分给到挑战者,部分直接销毁。如何证明欺诈,根据和L1交互程度的不同,分为交互式欺诈证明和非交互式欺诈证明,下面会详细解释。
第二种是零知识证明,每次存入状态都需要给出证明,证明会在L1进行验证,如果验证根hash值是正确的,代表发布者的发布无误,这里的证明用到了零知识证明相关研究。
本文咱们主要讲解欺诈证明,关于零知识证明,后面我会有一个专门的课题来介绍零知识证明
二. 欺诈证明
欺诈证明是一种技术机制,在使用 Optimistic Rollups (ORs) 的去中心化应用程序 (dApp) 生态系统中用作债券,这是一种侧链,旨在降低 dApp 在区块链平台上可能遇到的费用和延迟。负责处理 OR 的排序器必须在其工作中包含欺诈证明,以激励良好的表现。排序者根据共识规则处理汇总会获得经济奖励,并通过在破坏它们时丧失其欺诈证明而受到经济惩罚。
欺诈证明的主要优势在于,并非每次状态转换都需要它们,但只有当事情发生故障时才需要它们。因此,它们需要更少的计算资源,并且更适合可扩展性受限的环境。这些协议的主要缺点源于它们的交互性:它们定义了多方之间的“对话”。对话要求各方——尤其是声称欺诈的一方——在场(活跃),并允许其他方通过各种方式打断对话。但问题的核心是协议将沉默(对新状态不存在挑战)解释为默示同意。事实上,攻击者可以尝试通过 DDoS 攻击来制造沉默的表面。
让我们描述一下概念协议:由于一个块可能包含不正确的状态转换,因此欺诈证明协议允许一个时间框架——争议时间延迟(DTD)——来质疑这个不正确的状态。该窗口以块为单位。如果 DTD 内没有提交欺诈证明,则认为 L2 状态转换是正确的。如果向智能合约提交了欺诈证明,并且发现它是正确的(即,在 DTD 中提交,并且确实证明了不正确的状态转换),它至少会导致智能合约恢复到最后正确的 L2 状态。可能会采取其他措施,例如对违规方的处罚。
DTD 持续时间的选择很重要:持续时间越长,检测到错误状态转换的概率就越高——这很好。但是,时间越长,用户必须等待的时间越长,例如提取资金——这很糟糕。
当没有挑战的时候,流程较为简单, 即将状态树的根hash 交易信息存入L1中。核心在于有挑战者发起挑战时,如何证明交易前状态树的根hash经过这一组交易可以变为新的状态根hash。这里有2种思路。
1.非交互式欺诈证明,即在L1上将这组交易重新执行一遍,看看执行过后的状态树 根hash值和传入的根是否一致即可。
2.交互式欺诈证明,由挑战者和发布者在L2上进行多轮挑战,最终挑战者锁定具体哪条指令具有欺诈性,由L1进行裁决。L1只需要执行存在争议的最小指令即可。
非交互式欺诈证明和交互式欺诈证明在 L2 对应的也有几个有名的项目,非交互式欺诈证明 optimistic, metis 和 boba, 交互式欺诈证明 arbitrim
1. 非交互式欺诈证明
下面以Optimism为例说明非交互式欺诈证明
1.1. 欺诈证明过程解析
非交换式欺诈,欺诈证明实现较为简单,将L2中执行的交易在L1中再完整执行一次,以确定状态根的hash是否一致来判断欺诈行为。

如上图所示,发布者发布信息到L1上,携带交易信息和新旧整体根hash, L1中的智能合约收到后会默认变更state为新的根hash,这时挑战者提出挑战,挑战者需要提供符合旧根hash的merkle状态树,L1智能合约通过旧的状态树执行完整的交易流程得到根hash和发布者提供的新根hash比较,不相等则说明有欺诈行为。
重新执行就会遇到一个问题,区块相关的属性会因为执行环境不同而发生变化。

如上图所示block.timestamp会获取当前区块的时间戳,但由于合约执行的环境不同得到的时间戳大概率是不一样的。我们看看Optimism是如何设计OVM来解决这一问题的。
1.2. OVM
为了解决在L2和L1运行智能合约时所处环境不一致的问题,Optimism使用了虚拟化技术(实际上就是使用封装方法屏蔽)的方式,让智能合约直接获取一些状态变为经过OVM封装后调用。
上面的那个例子,将不能直接调用block.timestamp,改为调用ovm封装的1个方法ovm_getTimestamp(非真实 随意命名)
contract OVM_ENV {
uint timestamp; //L1重新执行前调用该方法设置正确的L2 timestamp即可
funtion ovm_setTimestamp(t:uint) {
timestamp=t;
}
funtion ovm_getTimestamp() returns(uint) {
return timestamp;
}
}
####2. 交互式欺诈证明
以Arbitrum为例说明交互式欺诈
2.1. Arbitrum欺诈证明过程解析
下图是智能合约执行的过程就是推进状态变化的过程

如图所示,无论上L1上的状态树还是L2上的状态树,都是由一系列的交易(智能合约的执行也是一次交易的调用),推动状态转换的,而由于智能合约,交易又可以拆分为更小的步骤指令。所以就变成了下面的样子

我们的问题转化为证明状态树从状态A 经过N个指令变成了状态B,那么这个证明过程是否是可分解的呢?我们用分治的方式不难想到二分法,将1个大问题拆两个子问题,问题就变为证明状态A 经过前N/2个指令变成状态X和状态X经过后N/2个指令变成状态B。逐步二分最终定位到存在问题的指令,交由L1执行验证即可。
让我们完整描述整个运行过程,假设X是发布者 发布从状态A经过N条指令转移到状态B Y是挑战者。
Y向X提出挑战,要求给出经过 N/2条指令处的状态,X给出状态后,Y会自行验证是否正确。如果验证正确,则代表前N/2指令执行无问题,问题在后N/2,如果验证错误,则代表前N/2条指令执行就有问题。Y继续向X询问存在问题的指令区间N/2处状态,循环往复,直至找到有问题的指令(这里不是指令有问题,是执行指令前的状态无法通过执行指令得到执行指令后的状态)。
在实际应用中Arbitrum不是使用二分的方式,而是使用了K分,即每次将N个指令分为N/K组去寻找欺诈指令,效率更高。
2.2. AVM
Arbitrum 设计 AVM和EVM不同的核心点在于:AVM不仅仅要支持EVM完全兼容的执行逻辑,还要支持交互式欺诈证明的证明逻辑。
证明过程中,要保证当前程序计数器中指令的正确性。这时采取了类似区块链的做法,PC(当前的程序计数器位置)不仅存储操作码,而且存储PC+1处的hash值,这样就可以在指令执行过程中验证验证每个指令是否正确。
三. 总结
| 交互式欺诈证明 | 非交互式欺诈证明 | |
|---|---|---|
| EVM兼容性 | 无法做到完全兼容由于OVM使用虚拟化技术解决L1和L2运行环境不一致的问题,那么必然就会导致一部分在L1运行的智能合约代码到OVM运行时需要进行修改 | 可以完全兼容 |
| 处理成本 | 存在欺诈行为时由于非交互式欺诈证明需要在L1完全重新执行所有交易,所以会耗费大量gas费用。 | 存在欺诈行为时交互式欺诈证明只需要在L1执行有争议的1条指令,所以gas费用很少。 |
| 复杂合约的支持 | 由于合约需要在L1上重新执行,合约复杂度不能超过L1对合约复杂度的限制 | 可以支持更复杂的合约。 |
由上述对比来看交互式欺诈证明除了实现难度较高外,主要特性都优于非交互式欺诈证明。具有代表性非交互式欺诈证明使用者Optimism也准备切换到交互式欺诈证明。可以预见未来交互式欺诈证明将会是欺诈证明的主流。
欺诈证明大都存在1个问题较长的提款周期,这是因为需要足够多的时间,让挑战者提出挑战。受益于密码学的较新研究成果,zk-rollup将解决这一问题。