Web3 与去中心化存储
互联网演进
Web 1.0:只读互联网, 1989 年 Tim·Berners·Lee (万维网之父)提出创建了一种开放的协议用于研究信息的交流。之后 10 多年,很多公司创建了自己的静态网站,用于展示公司形象与产品,彼时的网站与用户没有互动,被称为只读网络。
Web 2.0 :能读能写, 随着社交媒体平台的出现,网络不再是只读的,演变成读写网络。除了向用户提供内容外,用户也可参与生成内容。我们现在绝大部分产品:微信、微博、知乎、抖音 都是 Web 2.0 的产品,在这些产品上,用户创作的内容都保存在互联网巨头的服务器里,用户不真正拥有数据所有权。
Web 3.0:能读能写能拥有 ,最初由伯纳斯·李于 2006 年提出,更加强调用户的自主性,Web3 于 2014 年由Gavin Wood (Polkadot 创世人)提出,更加强调了去中心化概念与使用区块链技术创建用户可拥有的应用。
Web 3.0 与 Web3 概念上稍有区别,Web 3.0 强调互联网演进代际,Web3 表示使用区块链技术栈创建的应用。
Web3 技术堆栈
现在的 Web 2.0 应用,通常的技术架构是这样的:
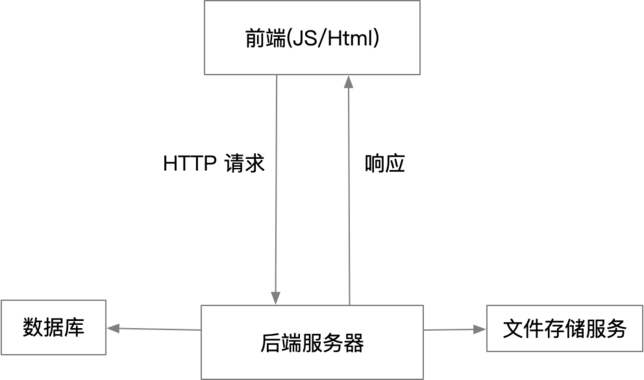
前端呈现应用的界面,也是用户交互的接口,前端所显示的内容通过 HTTP 请求后端服务器获取。后端服务器还会连接数据库及文件存储服务。数据库利用如 Mysql, PostgreSql 等,来存储用户数据、应用运行数据等,文件存储用来保存图片、音视频流文件等。
而 Web3 应用,技术架构则有所不同:
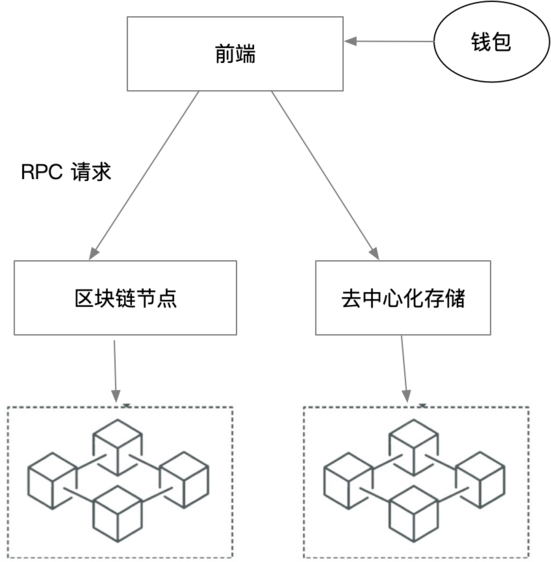
在前端部分,通过用户钱包来确保用户持有自己的数据(资产),在后端,核心应用逻辑通过链上智能合约处理,前端的交易发送给区块链节点,有区块链节点广播到区块链网络里。
一个应用,还有一个很重重要的部分是文件存储,在 Web2 里,所有的数据(包括大文件)都保存在中心化数据库中,但作为一个去中心化的 web3 应用,如果把文件保存在中心化服务器中,就面临配篡改及删除的分享。而我们之前介绍的区块链只适合交易数据的存储和执行,这就要引出一个新的角色:去中心化存储。
去中心化存储
前面介绍的比特币、以太坊、Polygon 等区块链,主要用于执行逻辑,是一个去中心化的计算平台,并不是为存储大量数据而设计的。当我们需要保存图片、音频、视频等内容时,则需要适合大数据的存储方案。
有很多项目在探索解决去中心化存储问题,其中两个最流行的项目是 IPFS 及 Arweave 。
IPFS 协议
IPFS目标是取代HTTP去构建一个更好的去中心化的Web。现有的HTTP网络服务,基于IP寻址的,就是IP找到内容所在的服务器,然后再与服务器交互。而在IPFS的网络里是根据内容寻址的,我们上传到IPFS的文件都会产生哈希值,无需知道文件存储在哪里,通过哈希值就能够找到这个文件。
当用户在 IPFS 网络上上传文件时,IPFS 协议会为文件分配了一个唯一的标识符(使用 Hash 算法),称为内容标识符 (CID)。 当用户想访问这个文件时,可以使用这个CID并询问网络上哪个节点拥有它对应的文件。任何拥有该文件的节点会将文件发送给请求的用户。一旦用户收到文件,用户的计算机就会存储该文件的副本,同时该用户将成为文件的另一个提供者。使用 CID 来寻找内容,带来一个很重要的特性,确保内容可信,因为内容不会被篡改,因为根据 Hash 的性质,只要内容修改,其对应的 CID 也不一样。
用户通过指向文件的内容(CID)而不是文件所处的位置(url)来访问文件,这种模式被称为基于内容的寻址,在 IPFS 网络中,使用ipfs://file_cid 形式访问文件。
备注:由于IPFS 协议,目前浏览器支持都还不是很多,当前Brave、Firefox 已经在浏览器中加入了IPFS 协议,Chrome 还没有支持,要通过 ipfs 访问文件需要安装
IPFS Companion浏览器插件,或通过 IPFS 网络来访问文件。
需要注意的是:IPFS 不是一个链,而是一个点对点的文件存储访问(超媒体)协议。IPFS 背后的团队发布的 FileCoin 则是一个区块链,激励节点来存储数据。
Arweave
Arweave 项目目标是实现去中心化的永久存储,Arweave 是一个区块链网络,数据保存在网络中的区块里。在 Arweave 网络中,单个节点是无法保存全量数据的,Arweave 如何在节点部分存储的情况下,确保内容不丢失呢?Arweave 引入了一个称为 blockweave 的结构,每个区块都与之前的两个区块相连,矿工需要在本地随机储存一个之前的区块(回忆块),才能生成新区块,而且存储保存之前的稀有区块的矿工有更大的概率去竞争到出块奖励,在 blockweave 上, 数据反复被储存在不同区块上,即便有矿工离开,也不会丢失数据,保护了数据的安全,同时由于鼓励保存稀缺块,也会促使所有的数据被“平等”保存。
区块链计算 + 去中心化存储
对去中心化存储有明显需求的是 NFT 类应用,多数的开发者选择的开发方式是,将NFT的底层元数据和图像数据保存在去中心化存储网络中,将对应的存储标识如CID 记录到区块链智能合约中,同时把与智能合约交互的前端也托管到去中心化存储中。从而得到一个“完全”去中心化、不可停止的 Web3 应用。